
PCA在数据科学中的应用:理论、算法与Python实现
主成分分析是数据科学中一种常用的降维技术,通过提取数据中最重要的特征方向,从而简化数据结构,提高数据处理效率,本文将深入探讨主成分分析背后的数学原理,详细解析其算法步骤,并通过Python代码示例展示如何在实际应用中使用sklearn库进行主成分分析,无论你是数据科学的新手还是有经验的从业者,这篇文章都将为你提供有价值的见解和实用技巧。
一、什么是主成分分析?
主成分分析是一种统计方法,用于通过正交变换将一组可能相关的变量转换为一组线性不相关的变量,这些线性不相关的变量称为主成分,主成分分析常用于探索性数据分析和数据预处理,以减少数据集的维度,同时尽量保持原数据方差。
二、主成分分析的数学原理
1. 数据矩阵与协方差矩阵
假设我们有一个n样本p变量的数据集,表示为一个n×p的数据矩阵X,主成分分析的目标是找到一个投影矩阵W,使得投影后的数据Y(即X乘以W)具有最大的方差,我们需要计算数据的协方差矩阵Σ:
\[ \Sigma = \frac{1}{n-1} X^T X \]
2. 特征值分解

下一步是对协方差矩阵进行特征值分解:
\[ \Sigma v_i = \lambda_i v_i \]
λ_i是特征值,v_i是对应的特征向量,特征值的大小表示数据在其对应特征向量方向上的方差大小,主成分分析的核心思想是选择最大的特征值所对应的特征向量作为主成分。
3. 选择主成分
我们会选择前k个最大特征值所对应的特征向量组成投影矩阵W:
\[ W = [v_1, v_2, \ldots, v_k] \]
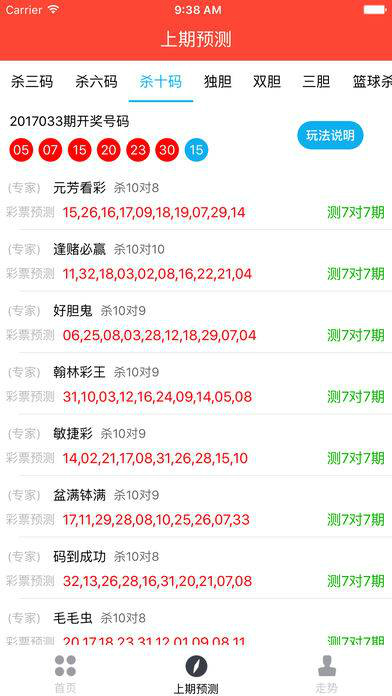
这样,我们就可以将原始数据投影到选定的主成分上,得到降维后的数据:
\[ Y = XW \]
三、主成分分析的算法步骤
1、标准化数据:为了使不同量纲的数据具有可比性,需要对数据进行标准化处理。
2、计算协方差矩阵:使用标准化后的数据计算协方差矩阵。
3、特征值分解:对协方差矩阵进行特征值分解,得到特征值和特征向量。
4、选择主成分:根据特征值的大小,选择前k个特征向量作为主成分。

5、投影数据:将原始数据投影到选定的主成分上,得到降维后的数据。
四、Python实现主成分分析
Python中有许多库可以实现主成分分析,其中最流行的是scikit-learn库,下面是如何使用scikit-learn进行主成分分析的示例代码。
导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
加载示例数据集
data = load_iris()
X = data.data
y = data.target
创建PCA对象,指定主成分数
pca = PCA(n_components=2)
拟合PCA模型并进行降维
X_r = pca.fit_transform(X)
打印解释方差比例
print("解释方差比例:", pca.explained_variance_ratio_)
可视化降维后的数据
plt.figure(figsize=(8, 6))
scatter = plt.scatter(X_r[:, 0], X_r[:, 1], c=y, cmap='viridis', edgecolor='k', s=100)
legend1 = plt.legend(*scatter.legend_elements(), title="Classes")
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of Iris Dataset')
plt.show()主成分分析作为一种经典的降维技术,在数据科学领域有着广泛的应用,通过理解其背后的数学原理和掌握其在Python中的实现方法,我们可以更好地应用主成分分析来处理高维数据,提高模型的性能和可解释性,希望本文能为你提供有关主成分分析的全面了解,并在实际应用中有所帮助。



 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号